
In the good old days, databases had a relatively simple job: help with the monthly billing, deliver some reports, maybe answer some ad hoc queries. Databases were important, but they weren’t in constant demand.
Today the picture is different. Databases are often tasked with powering business operations and hyperscale online services. The flow of transactions is incessant, and response times need to be near-instantaneous. In this new paradigm, businesses aren’t just informed by their database—they’re fundamentally built on it. Decisions are made, strategies are drafted, and services are personalized in real time based on vast streams of data.
Relational databases sit at the epicenter of this seismic shift. Their role transcends storage. It extends to processing complex transactions, enforcing business logic, and serving real-time analytical insights. The structured nature of relational databases, coupled with the innate ability to ensure the atomicity, consistency, isolation, and durability (ACID) of transactions, makes them indispensable in a world where data forms the core of business strategies.
To meet the demands of modern applications, relational databases need a radically new architecture. The must be designed from the ground up to handle voluminous data and transaction loads, resist different types of failure, and function seamlessly during times of peak demand without manual intervention or patchwork scaling strategies.
This architecture must be intrinsically scalable and reliable. Those two qualities can’t be bolted on. They have to be fundamental to the design. Scalability allows the database to efficiently accommodate fluctuating workloads. Reliability ensures consistent performance, preventing data loss or downtime that could critically impinge business operations or decision-making.
TiDB is a prime example of this new database architecture. It is an open-source distributed SQL database designed for the most demanding applications, scaling out to handle data volumes up to a petabyte in size. In this article we’ll explore the architectural features that give TiDB its scalability and reliability.
 PingCAP
PingCAPTiDB design fundamentals
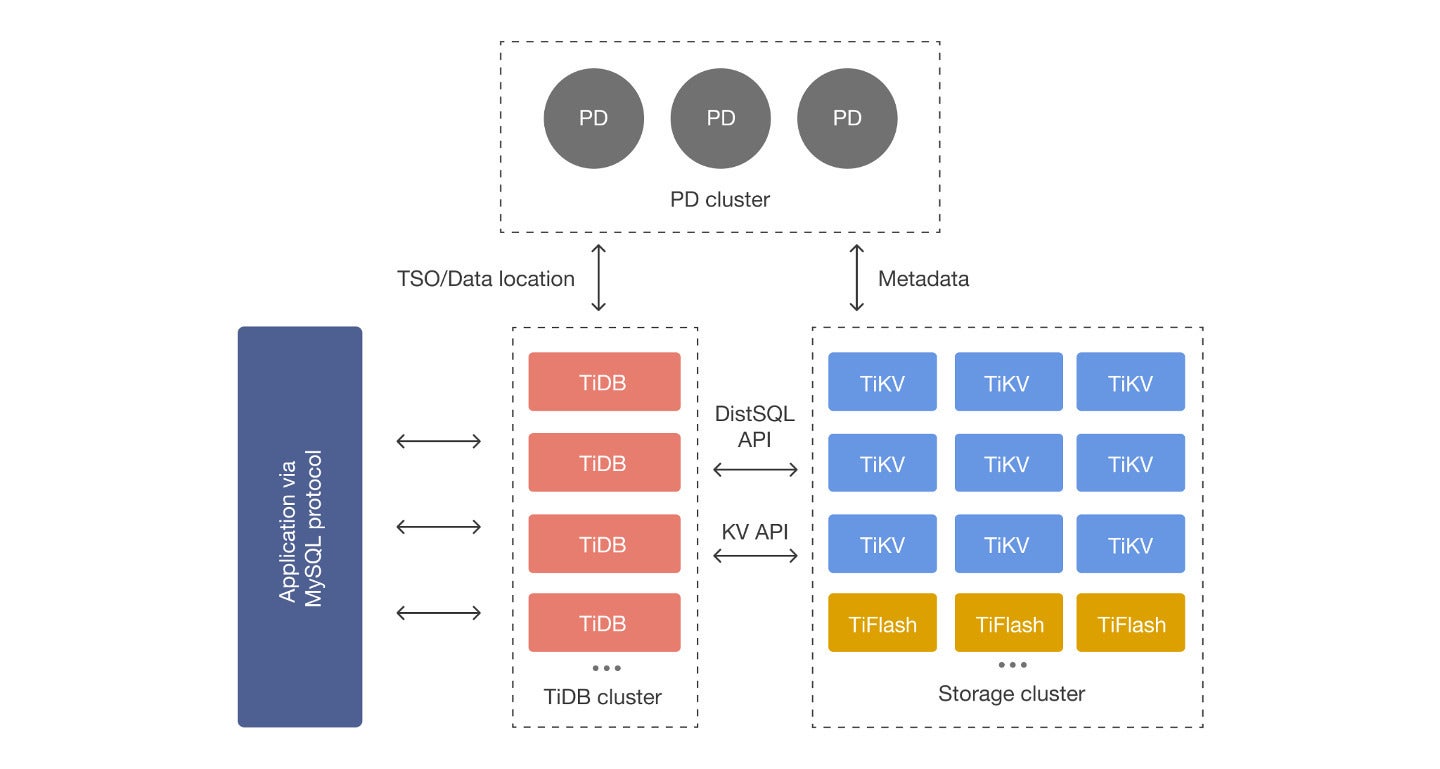
A cornerstone of TiDB’s architecture is its decoupling of storage and compute. Each of those two components can scale independently, ensuring optimal resource allocation and performance even as data needs evolve. This enables organizations to make the most efficient use of their hardware, enhancing cost-effectiveness and operational efficiency.
Another key design element is TiDB’s support for native horizontal scaling, or scale-out. Traditional transactional databases struggle with increasing data volumes and query loads. The easiest solution is to scale up—basically, to switch to more powerful hardware. However, there are limitations on the hardware of a single machine. TiDB automatically scales out to accommodate growth in transactions and data volumes. By adding new nodes to the system, TiDB keeps performance and availability consistent, even as data and user demands increase.
Another benefit to native horizontal scaling is that it eliminates the need for complex, disruptive sharding operations. The idea behind sharding is to speed up transactions and improve reliability by splitting the database into smaller, more manageable chunks, stored in separate database instances on separate physical media. In practice, maintaining a sharded system involves untold hours of manual work to keep each of the shards in optimal condition. Native horizontal scaling eliminates this burden. The database grows as needed, allowing it to manage unexpected spikes in demand—say, a surge in e-commerce traffic on Black Friday.
 PingCAP
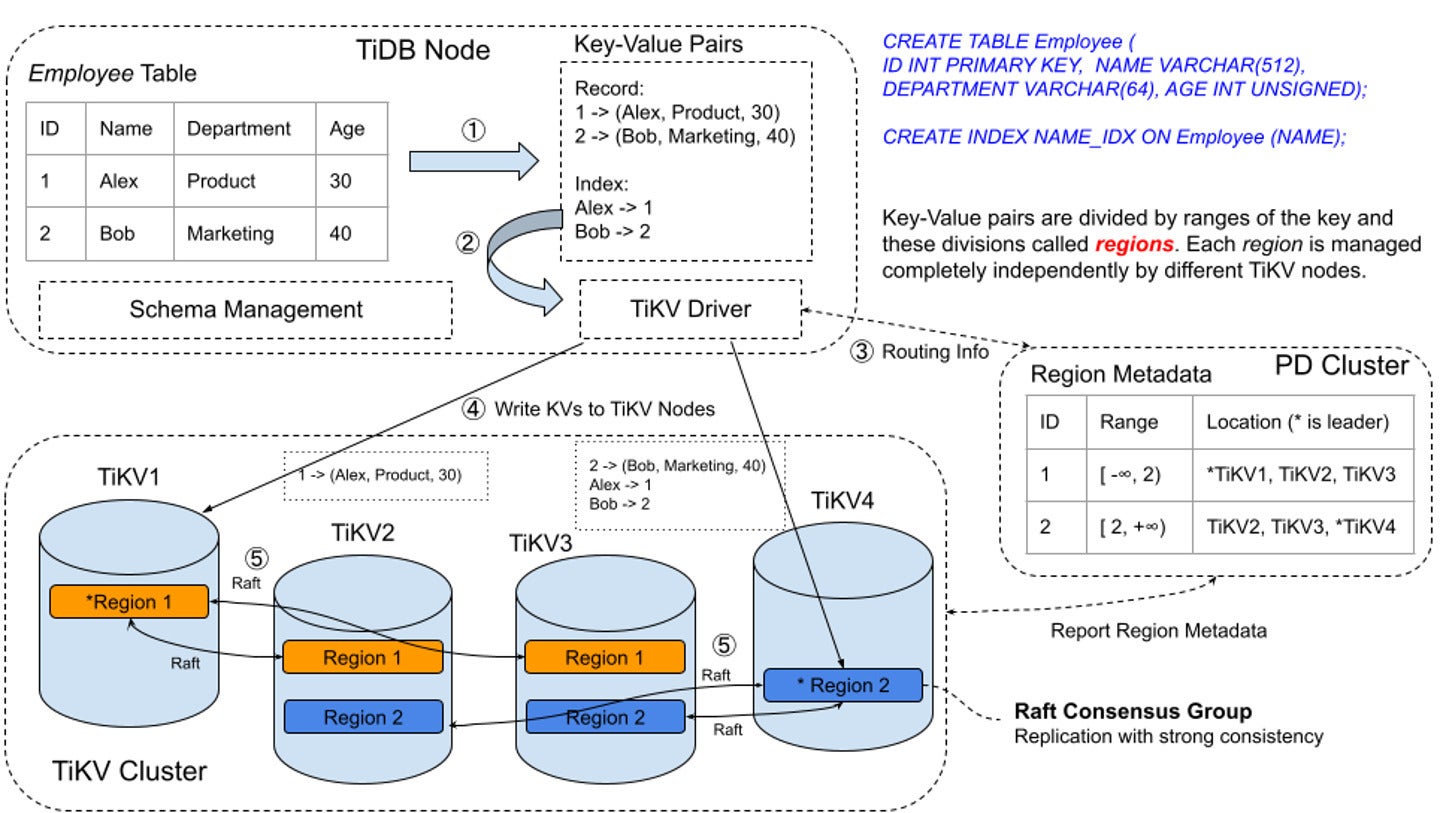
PingCAPTiKV is TiDB’s distributed, transactional, key-value storage engine. TiKV stores data in key-value format. It can split the data into small chunks automatically and spread the chunks among the nodes according to the workload, available disk space, and other factors. TiDB leverages the Raft consensus algorithm in its replication model to ensure strong consistency and high availability for the data chunks.
The Raft algorithm and replication in TiDB
The Raft consensus algorithm is another important building block in TiDB’s architecture. TiDB uses Raft to manage the replication and consistency of data, ensuring the data behaves as if it were stored on a single machine even though it’s distributed across multiple nodes.
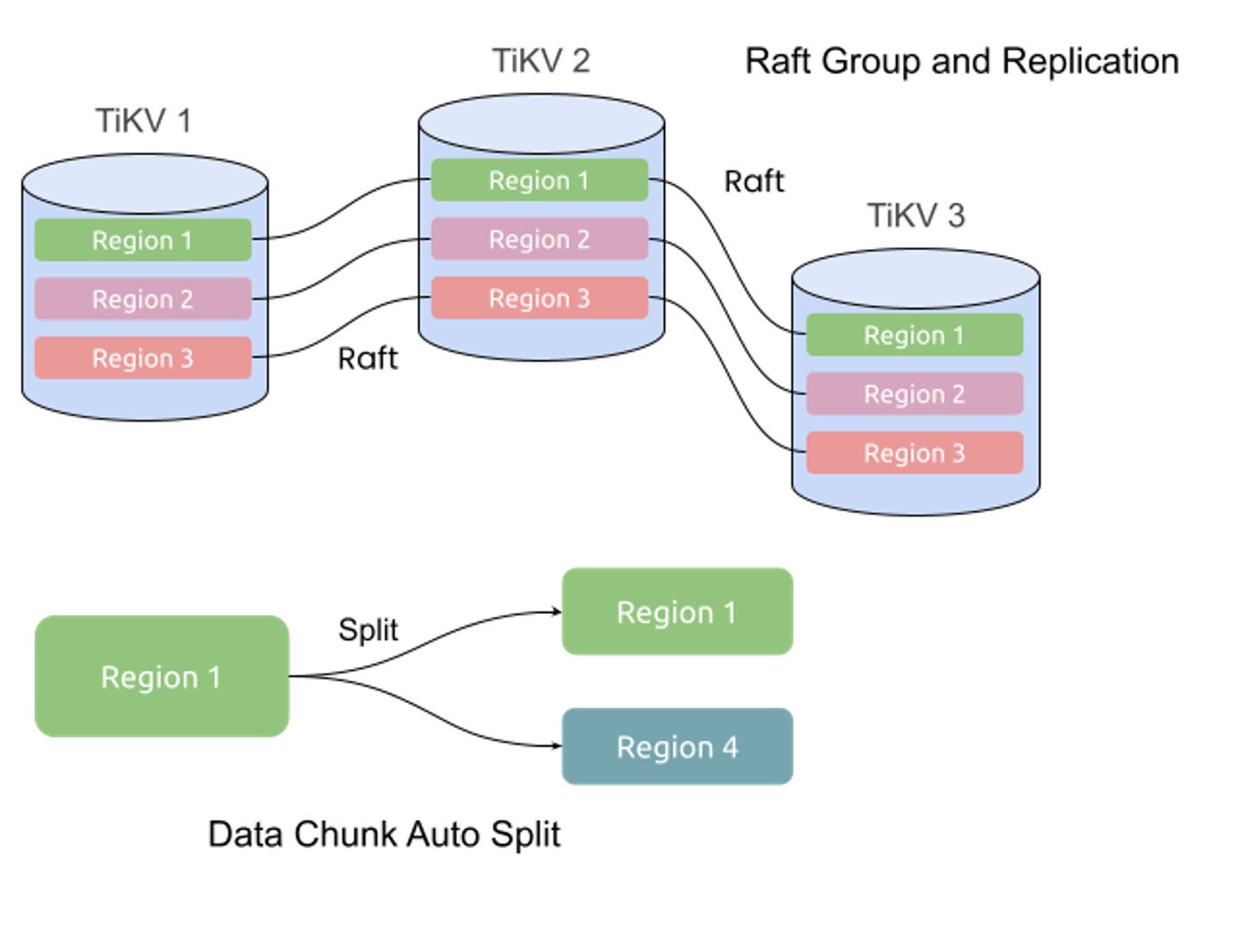
Here’s how it works. TiDB breaks down data into small chunks called regions. Each region acts as a Raft group, and can be split into multiple regions as data volumes and workloads change. When data is written to the TiDB cluster, it’s written to the leader node of the region. The Raft protocol ensures the data is replicated to follower nodes via log replication, maintaining data consistency across multiple replicas.
Initially, when a TiDB cluster is small, data is contained within a single region. However, as more data is added, TiDB automatically splits the region into multiple regions, allowing the cluster to scale horizontally. This process is known as auto-sharding, and it’s crucial to ensuring that TiDB can handle large amounts of data efficiently.
 PingCAP
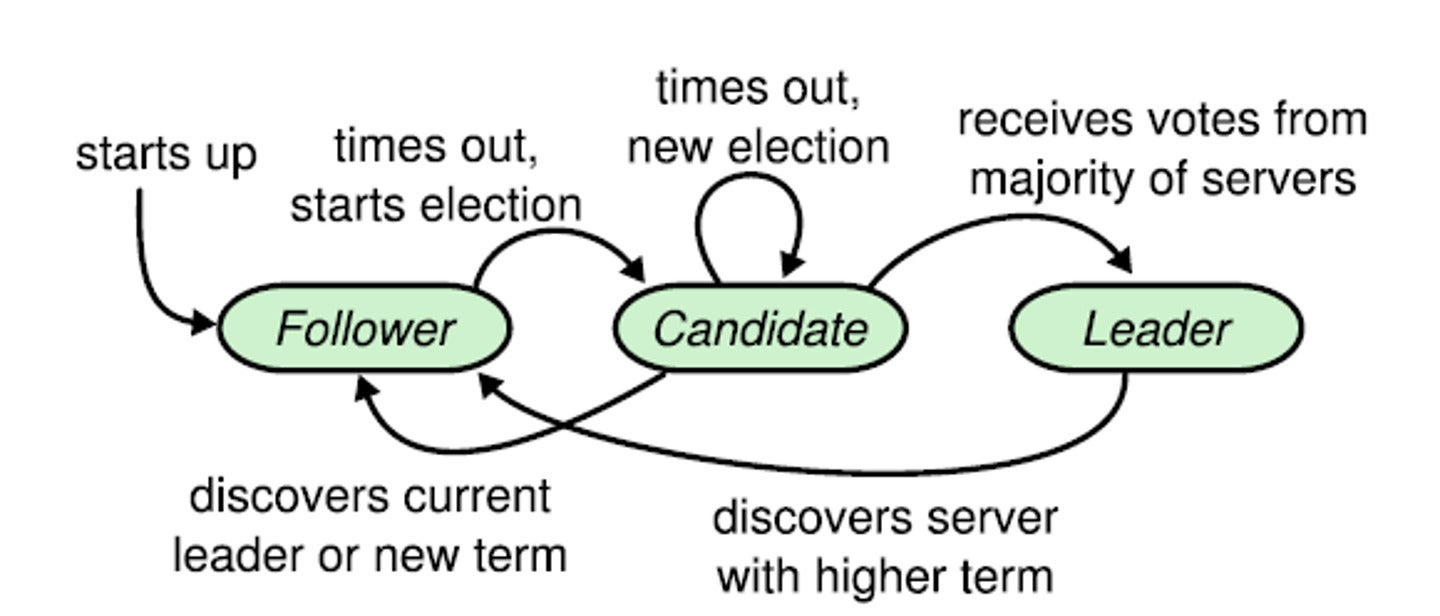
PingCAPIf the leader fails, Raft guarantees that one of the followers will be elected as the new leader, ensuring high availability. Raft also provides strong consistency, ensuring that every replica holds the same data at any given time. This enables TiDB to replicate data consistently across all nodes, making it resilient to node failures and network partitions.
 PingCAP
PingCAPOne of the key benefits of TiDB’s auto-split and merge mechanism is that it is entirely transparent to the applications using the database. The database automatically reshards data and redistributes it across the entire cluster, negating the need for manual sharding schemes. This leads to both reduced complexity and reduced potential for human error, while also freeing up valuable developer time.
By implementing the Raft consensus algorithm and data chunk auto-split, TiDB ensures robust data consistency and high availability while providing scalability. This seamless combination allows businesses to focus on deriving actionable insights from their data, rather than worrying about the underlying complexities of data management in distributed environments.
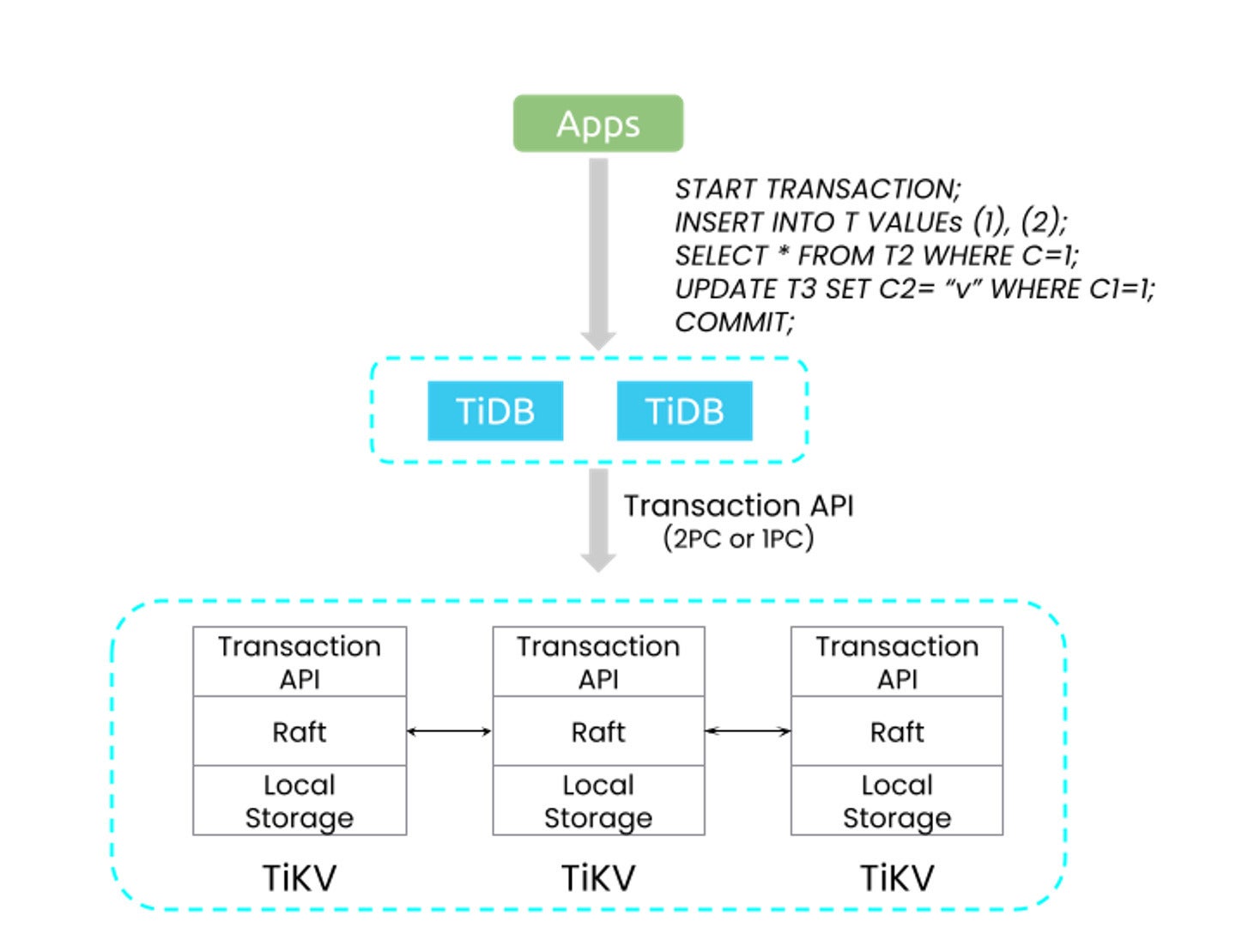
Distributed transactions in TiDB
Another building block of TiDB’s distributed architecture is distributed transactions, maintaining the essential ACID (atomicity, consistency, isolation, and durability) properties fundamental to relational databases. This capability ensures that operations on data are reliably processed and the integrity of data is upheld across multiple nodes in the cluster.
 PingCAP
PingCAPTiDB’s native support for distributed transactions is transparent to applications. When an application performs a transaction, TiDB automatically takes care of distributing the transaction across the involved nodes. There’s no need for developers to write complex, error-prone, distributed transaction control logic in the application layer. Moreover, TiDB employs strong consistency, meaning the database ensures that every read receives the most recent write, or an error in the case of ongoing conflicting transactions.
Because distributed transactions are natively supported by the TiKV storage engine, every node in the SQL layer can function as both a reader and a writer. This design eliminates the need for a designated primary node for writes, thereby enhancing the database’s horizontal scalability and eliminating potential bottlenecks or single points of failure. This is a significant advantage compared with systems that achieve scale by leveraging separate nodes to scale reads, while still using a single node to write. By eliminating the single-writer issue, TiDB achieves orders-of-magnitude higher TPS.
In discussing scalability, it’s imperative to look beyond data volumes and queries per second (QPS). Also important is the ability to handle unpredictable workloads and implement intelligent scheduling. TiDB is designed to anticipate and adapt to varying workload types and sudden demand surges. Its scheduling algorithms dynamically allocate resources, optimize task management, and prevent performance bottlenecks, ensuring consistent and efficient operation.
TiDB’s approach to scalability is also evident in its handling of large-scale database operations. TiDB’s architecture streamlines database definition language (DDL) tasks, which are often a bottleneck in large, complex systems. This ensures that even as a TiDB database grows, operations like schema changes perform efficiently.
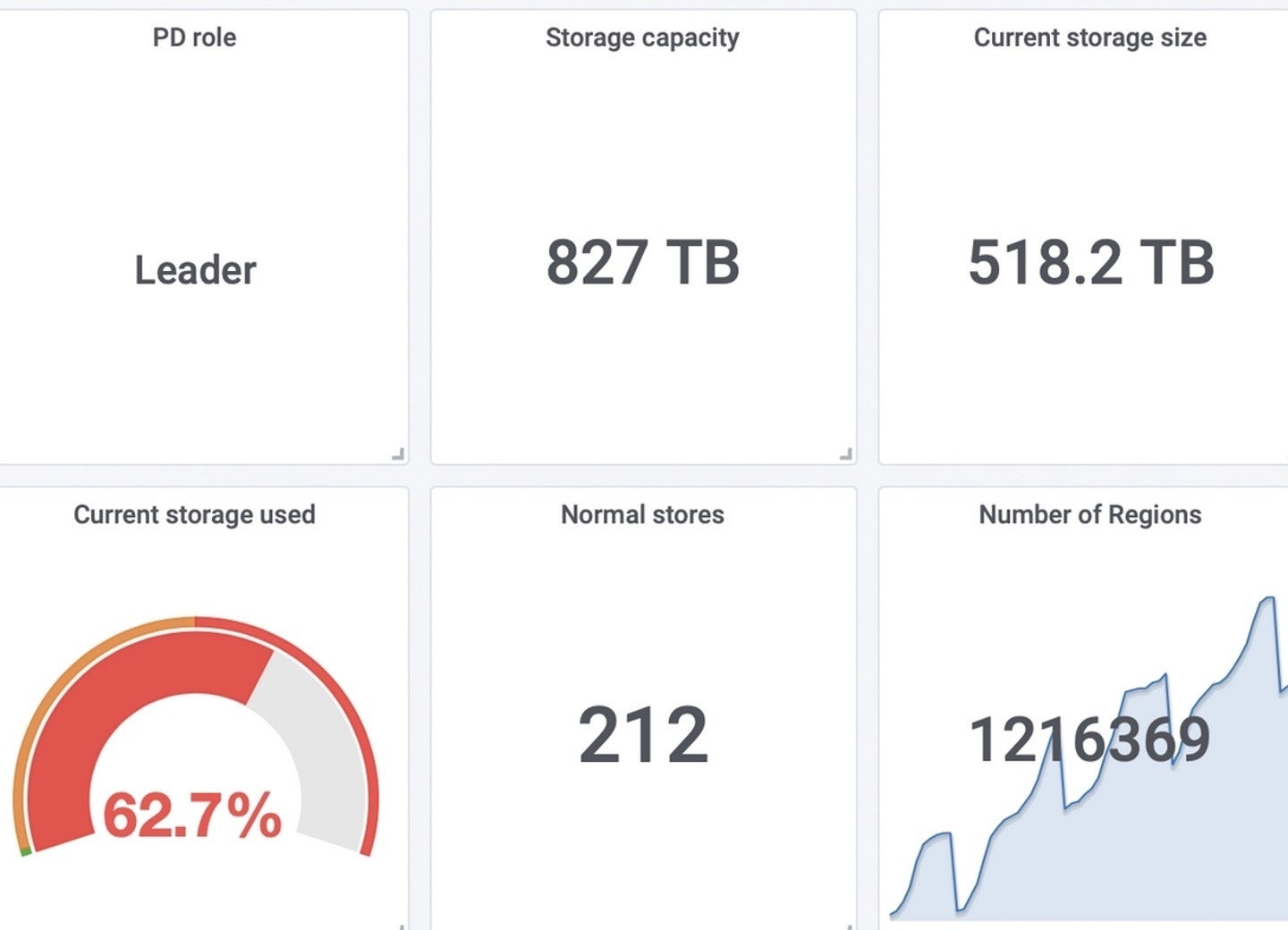
Here I’ll point you to two real-world examples of TiDB scalability. The first example shows a single TiDB cluster managing 500TB of data, encompassing 1.3 trillion records. The diagram below is the screenshot of the TiDB cluster monitoring dashboard.
 PingCAP
PingCAPThe second example, from Flipkart, the largest e-commerce company in India, shows a TiDB cluster scaling to 1 million QPS. Compared with Flipkart’s previous solution, TiDB achieves better performance and reduces storage space by 82%.
Reliability in TiDB
Applications and services depend on uninterrupted operation and robust data protection. Without them, users will quickly lose faith in the utility of the database system and its output.
TiDB offers native support for high availability to minimize downtime for critical applications and services. It also provides features and tools for quick restoration of data in the event of a major outage.
Replication and replica placement
We have discussed how TiDB uses the Raft algorithm to achieve strong, consistent replication. The location of replicas can be defined in various ways depending on the topology of the network and the types of failures users want to guard against.
Typical scenarios supported by TiDB include:
- Running different servers within a single rack to mitigate server failures
- Running different servers on different racks within a data center to mitigate rack power and network failures
- Running different servers in different availability zones (AZ) to mitigate zone outages
With a data placement scheduling framework, TiDB can support the needs of different data strategies.
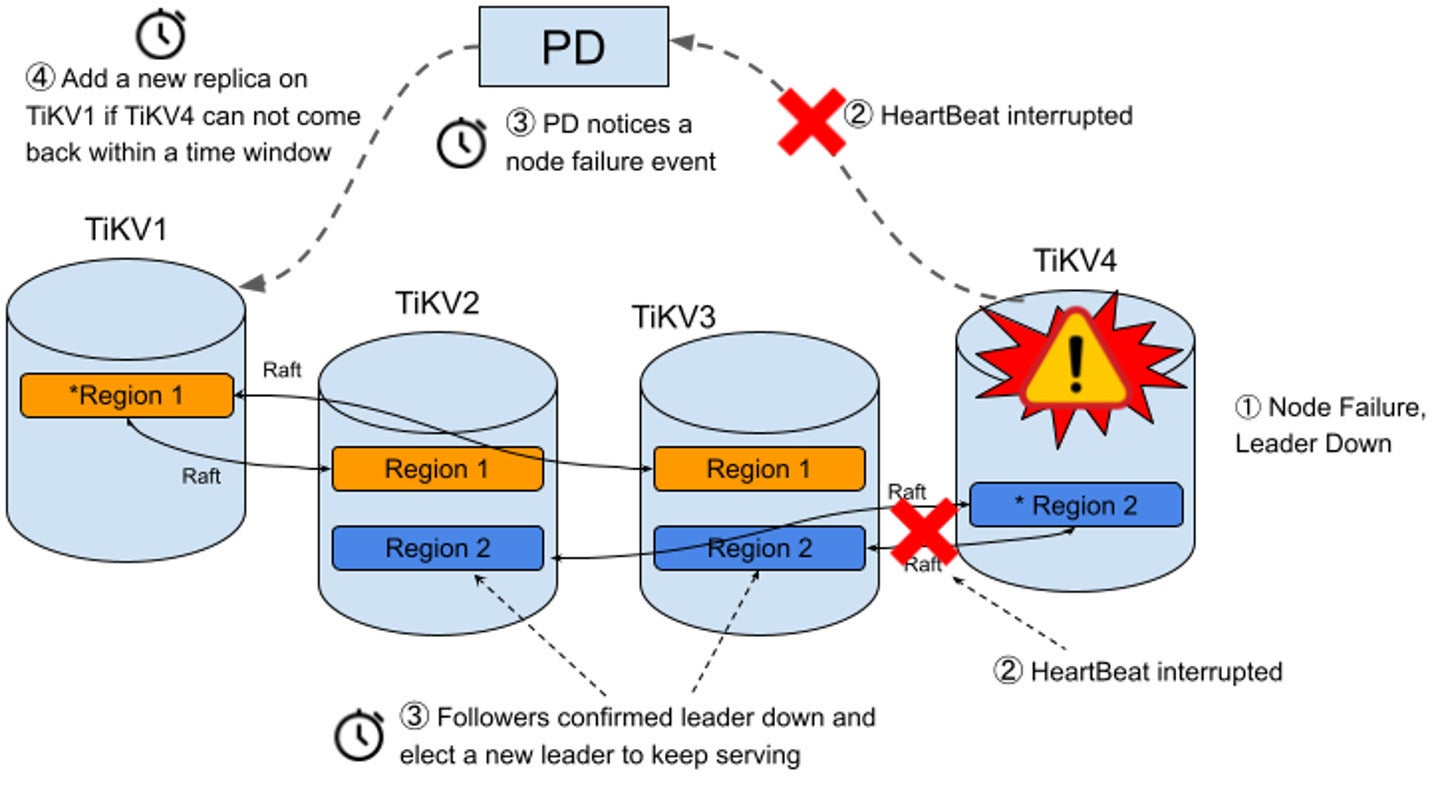
Auto-healing
For short-term failures, such as a server restart, TiDB uses Raft to continue seamlessly as long as a majority of replicas remain available. Raft ensures that a new “leader” for each group of replicas is elected if the former leader fails so that transactions can continue. Affected replicas can rejoin their group once they’re back online.
For longer-term failures (the default timeout is 30 minutes), such as a zone outage or a server going down for an extended period of time, TiDB automatically rebalances replicas from the missing nodes, leveraging unaffected replicas as sources. By using capacity information from the storage nodes, TiDB identifies new locations in the cluster and re-replicates missing replicas in a distributed fashion, using all available nodes and the aggregate disk and network bandwidth of the cluster.
 PingCAP
PingCAPDisaster recovery
In addition to Raft, TiDB provides a wide range of tools and features for disaster recovery including data mirroring, quick error rectification, continuous data backups, and full-scale restoration.
- TiCDC (change data capture): TiCDC mirrors changes in real time from the primary database to one downstream, facilitating a primary-secondary replication setup. In the event of a primary server failure, TiCDC ensures minimal data loss, as transactions are continually replicated. This system not only aids in disaster recovery but also helps in balancing loads and offloading read operations. The live mirroring of data changes is particularly crucial for applications requiring high availability, as it ensures the secondary setup can promptly take over with little to no downtime.
- Flashback: TiDB’s Flashback feature provides protection from one of the most unpredictable causes of disaster: human error. Flashback allows the database to be restored to a specific point in time within the garbage collection (GC) lifetime, so mistakes such as accidental data deletion or erroneous updates can be swiftly rectified without extensive downtime, maintaining operational continuity and user trust.
- PiTR (point-in-time recovery): PiTR continually backs up data changes, enabling restoration of the cluster to a specific point in time. This is crucial not only for disaster recovery, but also for business audits, offering the ability to review historical data states. PiTR provides an additional layer of data security, preserving business continuity and aiding with regulatory compliance.
- Full Backup and Restore: In addition to the aforementioned tools for specific use cases, TiDB is equipped with a comprehensive Full Backup and Restore feature, which provides the means to rebuild the entire cluster if necessary. In catastrophic failure scenarios, where data structures are compromised or a significant portion of data is corrupted, a full backup is indispensable. It ensures services can be restored to normalcy in the shortest time possible, providing a robust safety net for worst-case scenarios.
A database designed for change
The business world revolves around data. The worldwide surge in online financial transactions, fueled by business models like pay-as-you-go, has created an unprecedented demand for performance, along with the assurance that that performance will be there when it’s needed.
A distributed SQL database is what you get when you redesign relational databases around the idea of change. As the foundation for business applications, databases must be able to adapt to the unexpected, whether it be unexpected growth, unexpected traffic, or unexpected catastrophes.
It all comes back to scale and reliability, the capacity to perform and the trust in performance. Scale gives users the ability to make things the world has never seen before. Reliability gives them the faith that what they build will keep working. It’s what turns a prototype into a profitable business. And at the heart of the business, behind the familiar SQL interface, is a new architecture for a world where data is paramount.
Li Shen is senior vice president at PingCAP, the company behind TiDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Copyright © 2024 IDG Communications, Inc.

